Kafka transactions deep dive
Why Kafka has transactions ?
The most popular Kafka delivery guarantee is at least once. It means that the producing app is tuned for reliability - it is doing its best to persist messages in the log without data loss. The downside is the possibility of duplicates. In case of publishing failure, the producer retries. The same applies to broker failures. While it provides background for many types of applications, for some it is not enough. What if my app has stronger consistency requirements? What if I need to ensure that the group of messages will be persisted exactly once to multiple topics, so all of them are appended to the log or none of them? That’s why transactions were introduced to Kafka. The main beneficiary was Kafka Streams. The motivation is broadly described in the Kafka Transactions proposal. In this post, however, let’s come up with an example similar to transactions in SQL databases.
Problem statement
Let’s say we have an online shop app, with three Kafka topics: purchases, invoices, and shipments. Whenever the customer buys
a product, the purchase event is produced. It is then processed and two other events are created:
shipment and invoice.
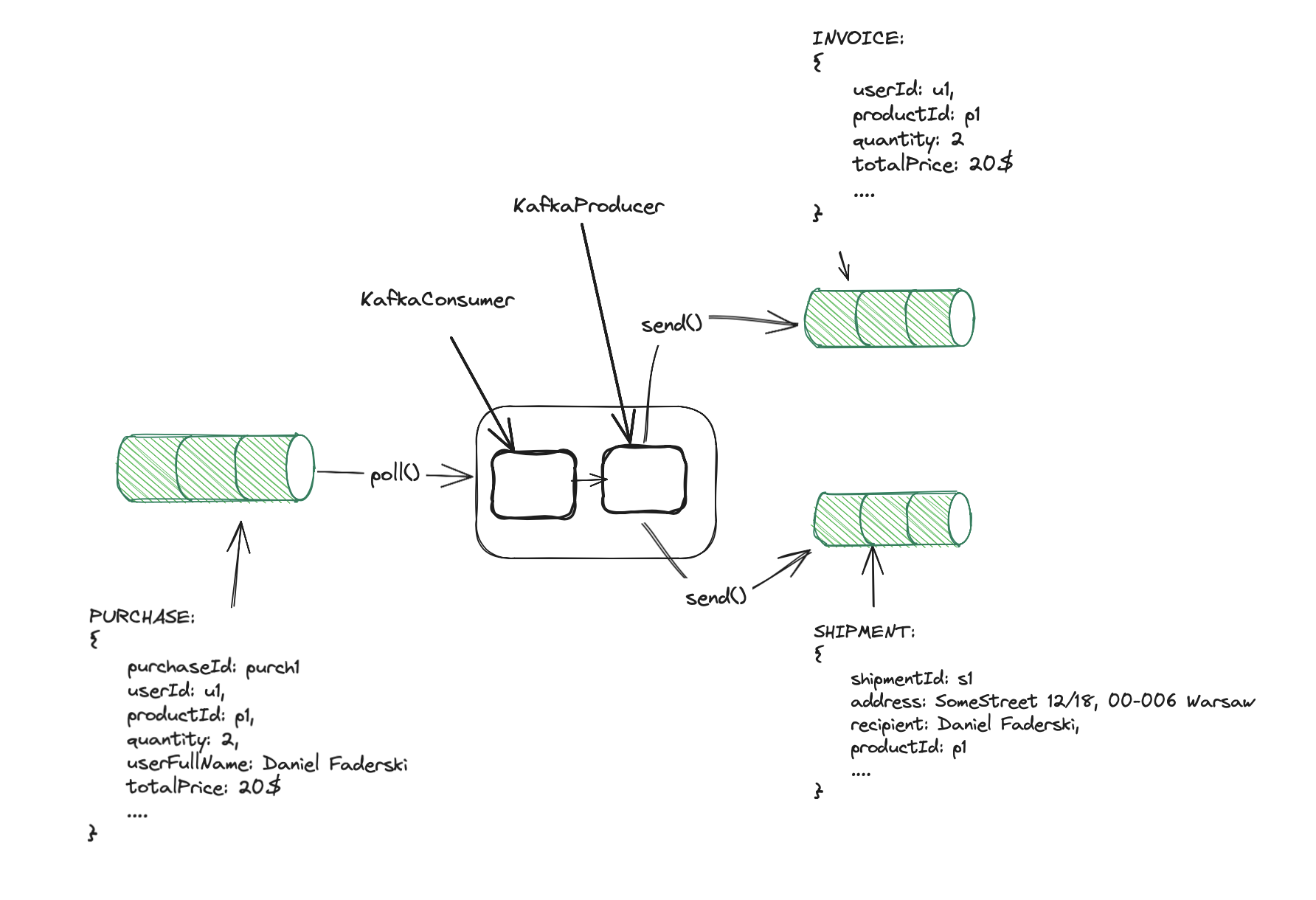
Obviously, we don’t want a situation where we make a shipment without processing the invoice. We don’t want the product
to be sent twice too. The shipment and invoice events should be published exactly once as a single unit.
Eliminating duplicates
Let’s focus on eliminating duplicates first. I’ve created an example processing for the above scenario.
KafkaConsumer polls message from Kafka. The message is then processed and two other events are produced. In the end, the consumer
commits the offset to Kafka, so we don’t process the same purchase message twice:
public void start() {
try {
consumer.subscribe(Collections.singleton(PURCHASE_TOPIC));
while (running) {
try {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(200));
for (ConsumerRecord<String, String> record : records) {
Purchase purchase = mapper.readValue(record.value(), Purchase.class);
Invoice invoice = new Invoice(purchase.userId(), purchase.productId(),
purchase.quantity(), purchase.totalPrice());
Shipment shipment = new Shipment(UUID.randomUUID().toString(), purchase.productId(),
purchase.userFullName(), "SomeStreet 12/18, 00-006 Warsaw", purchase.quantity());
// We block, then commit for simplicity. We should commit asynchronously when both messages are sent.
producer.send(new ProducerRecord<>(INVOICES_TOPIC, mapper.writeValueAsString(invoice))).get();
producer.send(new ProducerRecord<>(SHIPMENTS_TOPIC, mapper.writeValueAsString(shipment))).get();
consumer.commitSync();
logger.info("Successfully processed purchase event: {}", purchase);
}
} catch (Exception ex) {
logger.error("Error while processing purchase", ex);
}
}
} finally {
logger.info("Closing consumer...");
consumer.close();
}
}
Idempotent producer
Kafka has had an idempotent producer for a long time. It prevents duplicated published events. Unfortunately, it works only for a single producer session. Nevertheless, it is a good starting point from which we can progress.
Enabling idempotence
props.setProperty("acks", "all"); // this must be set to `all`. If not specified, it is implicitly set when idempotence enabled.
props.setProperty("enable.idempotence", "true"); // this enforces enabling idempotence
The native Java client has the idempotence enabled by default if there are no conflicting configurations.
To enforce idempotence set enable.idempotence to true. It will then validate and enforce proper configuration.
Idempotent producer enforces ACK all. We will cover why when describing guarantees.
Producer and broker internal state
Every time the idempotent producer sends a batch of messages, it remembers the sequence number of the last batch sent. The newly initialized producer starts with a 0 sequence number.
Every time a new message batch is produced, the sequence is increased. In case of sending retries, the batch sent twice with the same sequence will be rejected by a broker. The picture below presents the simplified state of the producer and broker when enabled idempotency.
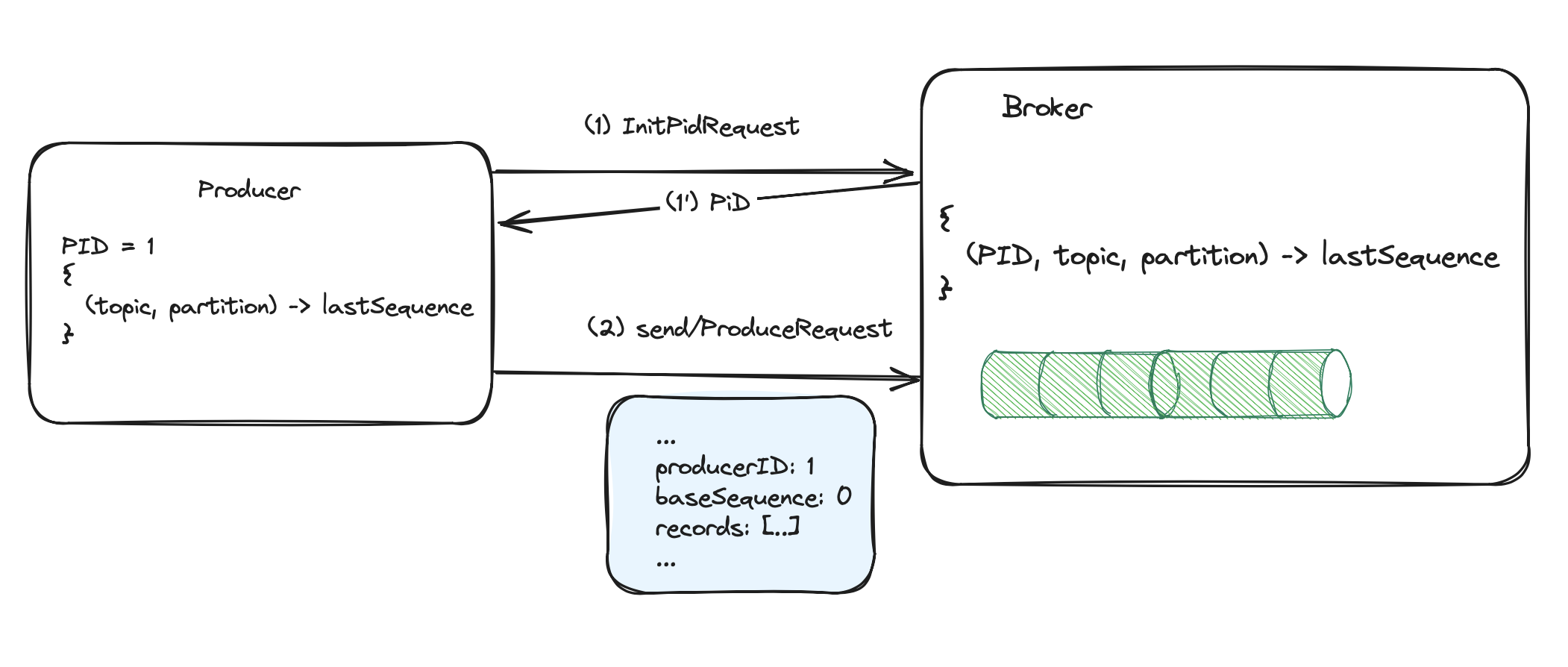
The producer has the ProducerId (PID) acquired by sending InitPidRequest(1) to any broker. Additionally, it keeps mapping
between (topic, partition) and the last produced sequence number to that partition. Messages are sent together with acquired PID
and baseSequence number (2). The baseSequence number is a sequence of the first message in the batch (lastSequence + 1).
Every consecutive batch successfully sent, increments sequence numbers by the size of the batch. The broker keeps in-memory mapping from
(PID, topic, partition) to the lastSequence number sent by the producer. This way, the broker knows what next baseSequence number
to expect (lastSequence + 1). In case of duplicated batch, the baseSequence number will not match the expected one
and request is rejected.
Guarantees in failures scenarios
ProduceRequesttimeout - while sending a batch of messages,KafkaProducermay fail to receive a response within a configured timeoutrequest.timeout.ms. What if the broker saved the message, but some network issue caused not receiving the response? From the producer’s perspective, the request failed, so it retries with the previously used sequence number. As we said before, the broker remembers which sequence numbers were already sent, so it knows what to expect next. If the first try saved a message, the broker then expects a higher sequence number and rejects retried messages with lower sequences. The producer getsDuplicateSequenceExceptionerror. It can safely ignore that and continue sending the next messages. No duplicates.- Producer restart - application publishing messages may restart or crash at any time. What if the producer sent the message,
it was persisted by the broker, and just before receiving the response the application restarted?
The new
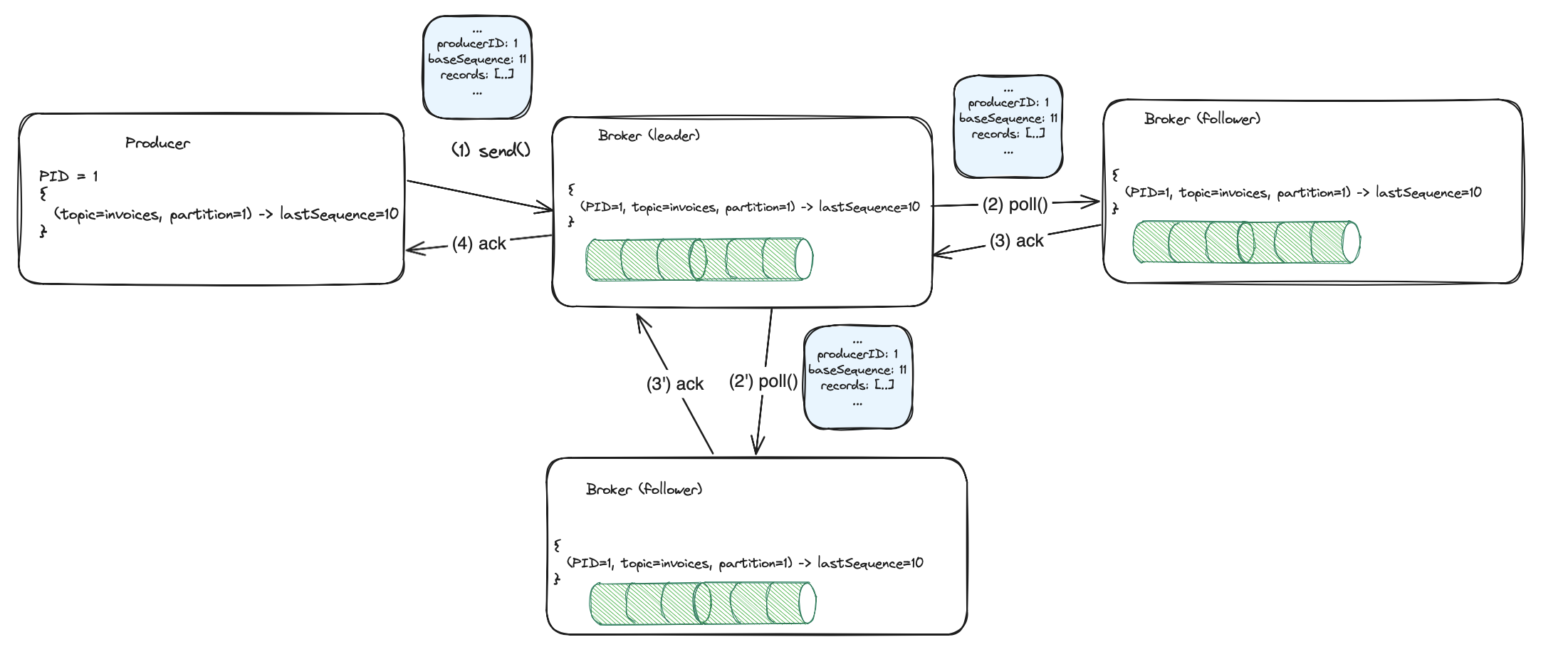
KafkaProducerwill be created, it will initialize by sendingInitPidRequest, and it will get a newPID. The broker will have a clear state for the newPID. In our example app, we commit offsets after successful publishing, so we didn’t do that before restarting. We’ll reprocess the last message, and send it with a completely newPIDand sequence number. We have a duplicate. - Broker restart - another scenario is when we publish a message to Kafka, it persists in the broker, but the broker restarted just before the response was sent back to the producer. Let’s recall what producer configuration is needed to enable idempotence.
props.setProperty("acks", "all"); // this must be set to `all`. If not specified, it is implicitly set when idempotence enabled.
props.setProperty("enable.idempotence", "true"); // this enforces enabling idempotence
We said before that idempotent producer enforces ACK all. It means that every
message published to the topic will be fully replicated to the configured number of in-sync replicas, before returning
a successful response to the client. This is not a post about replication, so for those of you who are unfamiliar with ACK-s, let’s
state that the message has to be replicated synchronously by some number of replicas. We previously stated, that every message sent
contains PID and sequence number. These attributes are stored in the log and replicated (together with data).
With every new message replicated from the leader, replicas build the same in-memory state. If the current leader fails,
the newly elected will have the state fully replicated (because of ACK all).
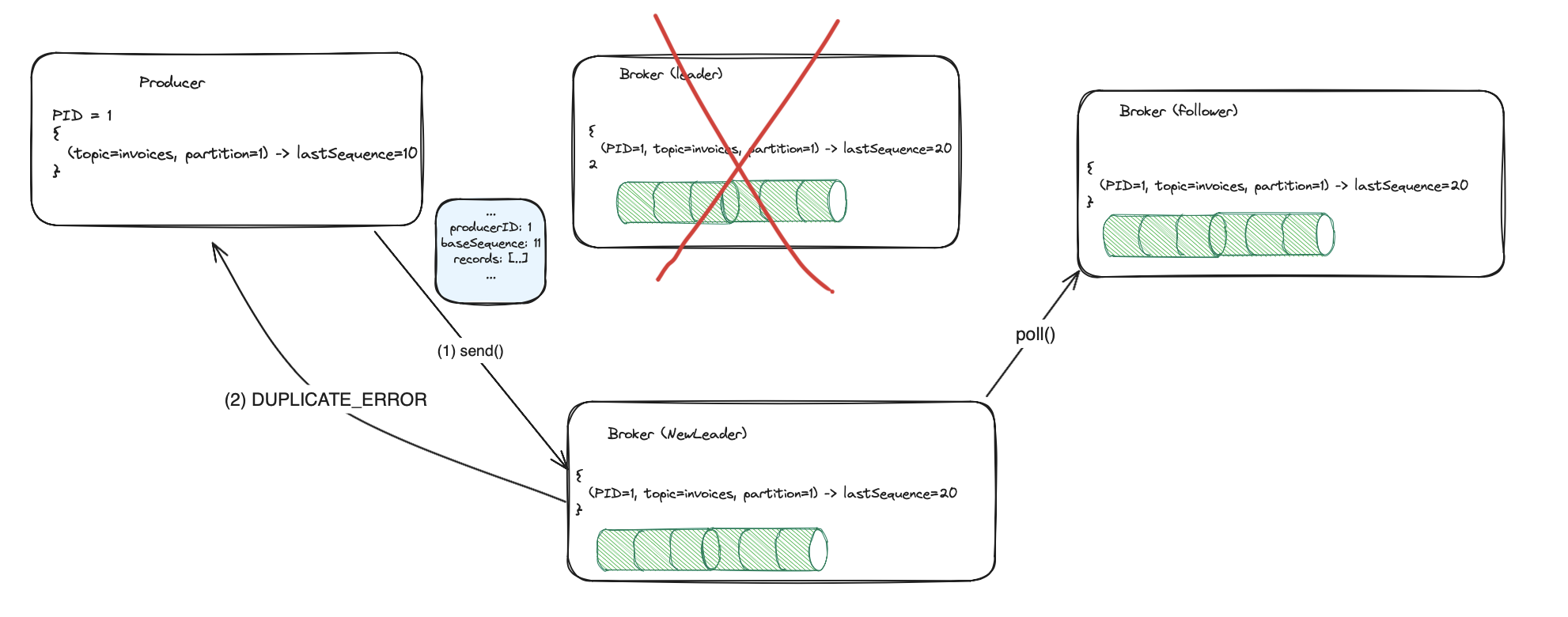
In case of retry and broker restart the idempotence prevents duplicates. The message was saved by the leader and
replicated by followers (2/2’). The producer retries sending to the new leader, which already has a proper in-memory
state built from the log. The new leader rejects duplicates. The producer gets DuplicateSequenceException,
but it can ignore that, and skip the retried message.
Why idempotent producer if not enough ?
As you see the idempotent producer is not a reliable solution for our case. It only prevents duplicates in a single producer session. The producer restart resets its state. Additionally, we still have no way of atomic writes to multiple output topics. We need stronger guarantees. Kafka transaction mechanism provides all of these.
Transactions
Before we get into guarantees Kafka transactions give, I find it helpful to first understand how they work. For now, let’s state that they provide atomic consume-transform-produce loop. It means that we can get an event from a Kafka topic, map it to another event, and publish the mapped value to another topic as a single unit. If any of the three steps fail (or we abort explicitly) nothing happens from the output topic consumers’ perspective.
Usage from client perspective
Full code is here. The verbose version:
private static Properties consumerProperties() {
Properties consumerProps = new Properties();
...
consumerProps.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "purchasesConsumerGroupId");
consumerProps.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false"); // offsets are managed by transactional producer
return consumerProps;
}
private static Properties producerProperties() {
Properties props = new Properties();
...
props.setProperty(ProducerConfig.ACKS_CONFIG, "all"); // this must be set to `all`, if not specified, it will be default for idempotence
props.setProperty(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true"); // this enables idempotence
props.setProperty(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "myProducer"); // this uniquely identifies the producer, even among restarts
return props;
}
public void start() {
try {
producer.initTransactions();
consumer.subscribe(Collections.singleton(PURCHASE_TOPIC));
while (running) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(200));
for (ConsumerRecord<String, String> record : records) {
try {
Purchase purchase = mapper.readValue(record.value(), Purchase.class);
String invoiceEvent = mapper.writeValueAsString(new Invoice(purchase.userId(), purchase.productId(),
purchase.quantity(), purchase.totalPrice()));
String shipmentEvent = mapper.writeValueAsString(new Shipment(UUID.randomUUID().toString(), purchase.productId(),
purchase.userFullName(), "SomeStreet 12/18, 00-006 Warsaw", purchase.quantity()));
producer.beginTransaction();
producer.send(new ProducerRecord<>(INVOICES_TOPIC, invoiceEvent));
producer.send(new ProducerRecord<>(SHIPMENTS_TOPIC, shipmentEvent));
Map<TopicPartition, OffsetAndMetadata> offsets = Map.of(
new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1));
producer.sendOffsetsToTransaction(offsets, consumer.groupMetadata());
producer.commitTransaction();
logger.info("Successfully processed purchase event: {}", purchase);
} catch (JacksonException ex) {
logger.error("Error parsing purchase message", ex);
} catch (Exception ex) {
logger.error("Error while processing purchase", ex);
producer.abortTransaction();
resetToLastCommittedPosition(consumer);
break;
}
}
}
} finally {
logger.info("Closing consumer...");
consumer.close();
}
}
The refined version:
producer.initTransactions();
...
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(200));
for (ConsumerRecord<String, String> record : records) {
...
producer.beginTransaction();
producer.send(new ProducerRecord<>(INVOICES_TOPIC, invoiceEvent));
producer.send(new ProducerRecord<>(SHIPMENTS_TOPIC, shipmentEvent));
...
producer.sendOffsetsToTransaction(offsets, consumer.groupMetadata());
producer.commitTransaction(); // or we can call producer.abortTransaction() too
The code does a similar thing as in our first approach with the idempotent producer. This time though it provides atomicity guarantees. It works like this:
- Initiate the producer and broker to enable transactions.
- For each
purchaseevent fetched by a consumer, produceinvoiceandshipmentevents to the output topics. - Add
purchasesconsumer offset to the transaction. - Commit - now all 3 things (2 events and 1 offset move) are atomically saved to Kafka, no partial results. If something wrong goes here, the transaction is aborted, and consumers (with proper isolation level) of the output topics don’t see aborted events.
[INFO]
The example creates a new transaction for each event consumed from the input topic. I’ve written it this way only for simplicity. It can be improved, by batching multiple input events into a single transaction.
Transaction components
We can go deeper into each part of the transaction. It’s time for drawings.
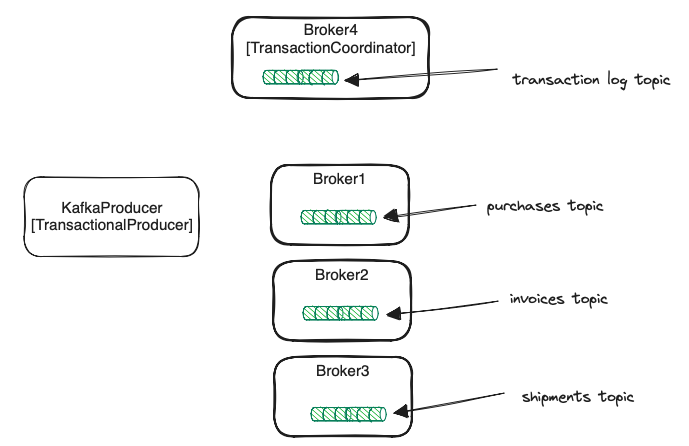
Transactional producer
To enable transactional producer we need to turn on idempotency and add another parameter: transactional.id.
props.setProperty("acks", "all");
props.setProperty("enable.idempotence", "true");
props.setProperty("transactional.id", "myProducer");
The transactional.id is a unique identifier provided by the client app for a producer,
and it has to be the same between producer restarts. Otherwise, we don’t get transactional guarantees.
Ok, but what does it mean to be the same? In an environment where we have multiple producer instances,
every transactional.id must map to a consistent set of input topic partitions. In our case:
- If source topic
purchaseshas two partitions [1, 2]. - If we have two instances of the app consuming from
purchases, and producing new events to the outputinvoices/shipmentstopics. - If one instance consumes from partition [1] and has a transactional producer producing to both output topics.
- If the second instance consumes from partition [2] and has a transactional producer producing to both output topics.
- Then after restart, the first instance must still consume from the partition [1] and must use the same
transactional.idfor its producer. - The same holds for the second instance.
Transaction coordinator
The transaction coordinator - is just a usual broker. Every broker can be a coordinator. It manages transactions for some set of producers.
Just like the SQL databases keep the WAL (write-ahead log) of the transaction’s operations, Kafka has a transaction log too.
It is an internal topic - __transaction_state. This topic is divided into 50 partitions by default. Broker being a leader
for some partition(s) of this internal topic can be assigned as a coordinator for specific producers. We’ll cover that later.
If you have more than 50 brokers, increase the number of transaction log partitions so each broker can be assigned
a partition as a leader. Transaction log is replicated to the follower replicas for availability
in case of coordinator failure.
Transaction steps
Initialization
producer.initTransactions();
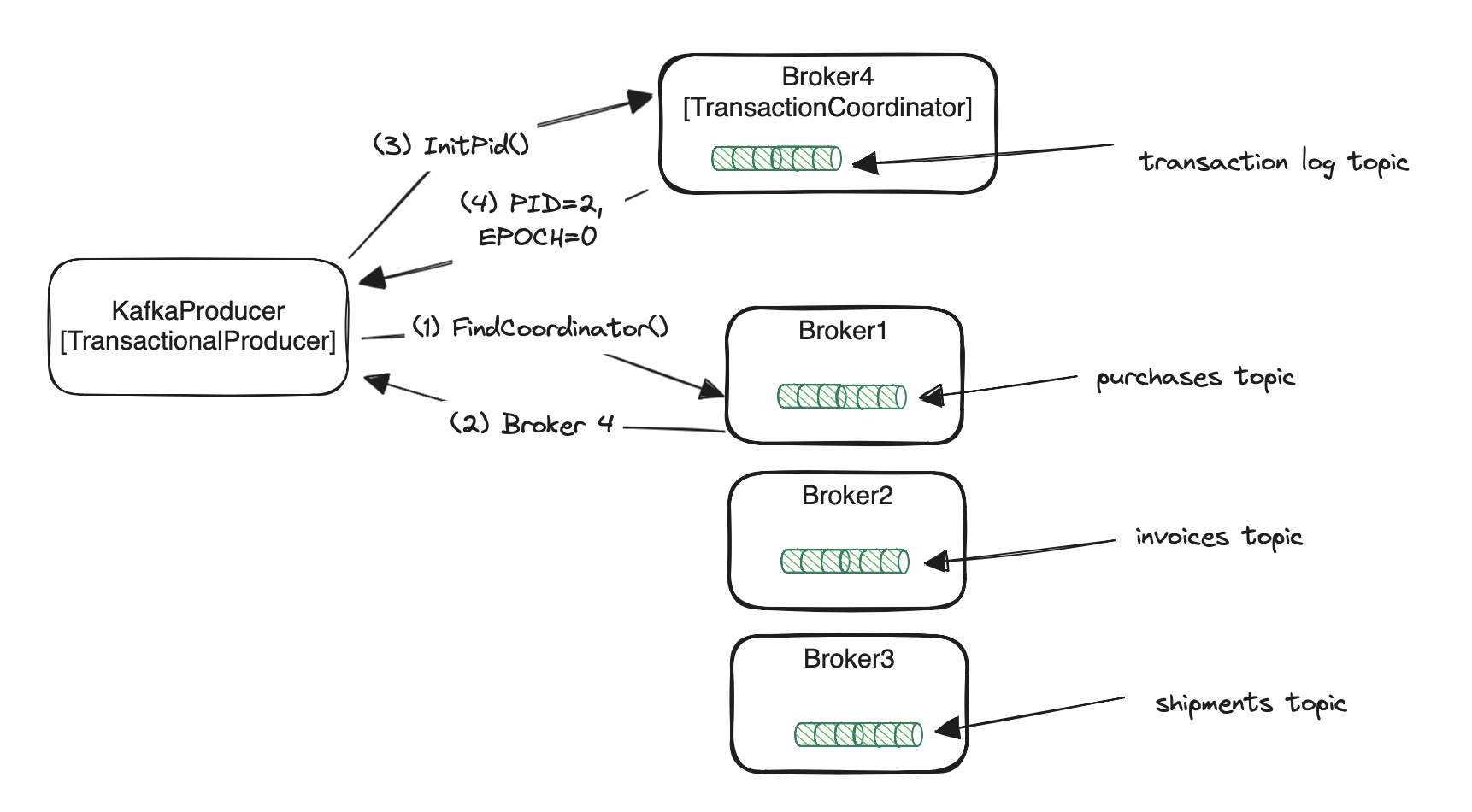
The first thing to do by a producer is to find its transaction coordinator. That’s why it sends FindCoordinatorRequest(1) to any broker.
The broker then finds the transaction coordinator and returns it to the producer (2). The coordinator search algorithm is quite simple.
It takes the hash from the producer’s transactional.id and does the modulo using __transaction_state topic partitions count.
The coordinator is the leader of the calculated partition number. Pseudocode:
var kafkaTransactionLogPartitionId = hash(transactional.id) % transactionStateTopicPartitionsCount;
var coordinatorId = leaderOf(kafkaTransactionLogPartitionId);
Once the producer knows its coordinator it can send an InitPidRequest request for acquiring the PID (3). The response (4) contains
the PID and epoch number. Just like in case of the idempotent producer the former helps in detecting duplicates across a single producer session.
The latter though is used for distinguishing between instances of the same producer between restarts.
Let’s assume we have the following scenario:
- The producer with
transactional.idset tomyProducersendsInitPidRequestto the transaction coordinator and getsPID=2, epoch=0 - Some time passed and the producer hung for an unknown reason, so it was considered dead by an orchestration system.
- The new instance of the producer with the same
transactional.id(myProducer) was spawned. - After finding the coordinator, the new instance sends
InitPidRequest, but this time it getsPID=2, epoch=1in response. - When the first instance wakes up and tries to start a new transaction it is immediately fenced by the coordinator.
The epoch number sent by the old producer is
0, but the newest registered for thattransactional.idis1.
Producer and broker internal state
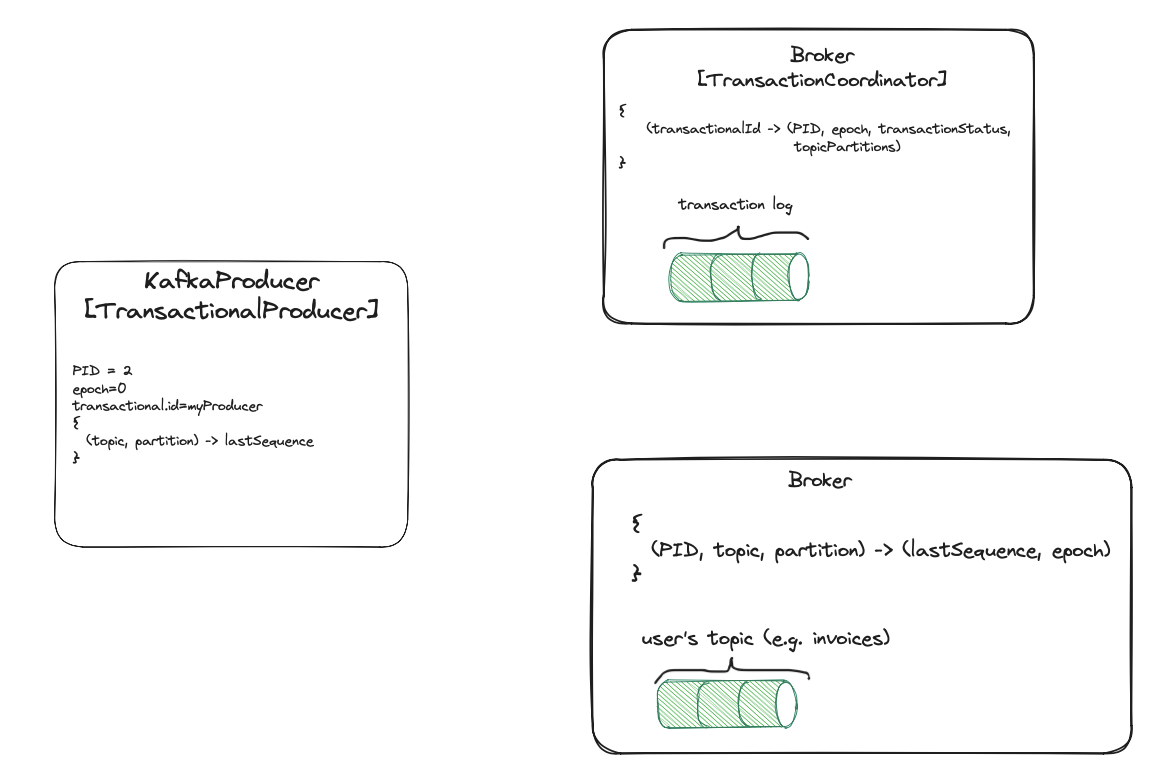
- Transactional producer avoids duplicates even in case of restarts. Similarly to the idempotent producer,
transactional
KafkaProducerkeeps the mapping from topic partitions to the sequence number. This time however, the producer can recreatePIDandepochnumber between restarts (because broker remembers them fortransactional.id). Theepochis used to fence zombie instances of the old producer with the sametransactional.id. - Transaction coordinator keeps mapping from
transactional.idto the producer (PID,epoch, outputtopicPartitionsinvolved in the transaction,transactionStatus). The exact implementation has more fields, but I’ve not included them for simplicity.
Staring transaction
producer.beginTransaction();
The producer makes a bunch of validation and changes its internal state to the in-progress stage. No external requests here.
Sending messages to brokers
producer.send(new ProducerRecord<>(INVOICES_TOPIC, invoiceEvent));
producer.send(new ProducerRecord<>(SHIPMENTS_TOPIC, shipmentEvent));
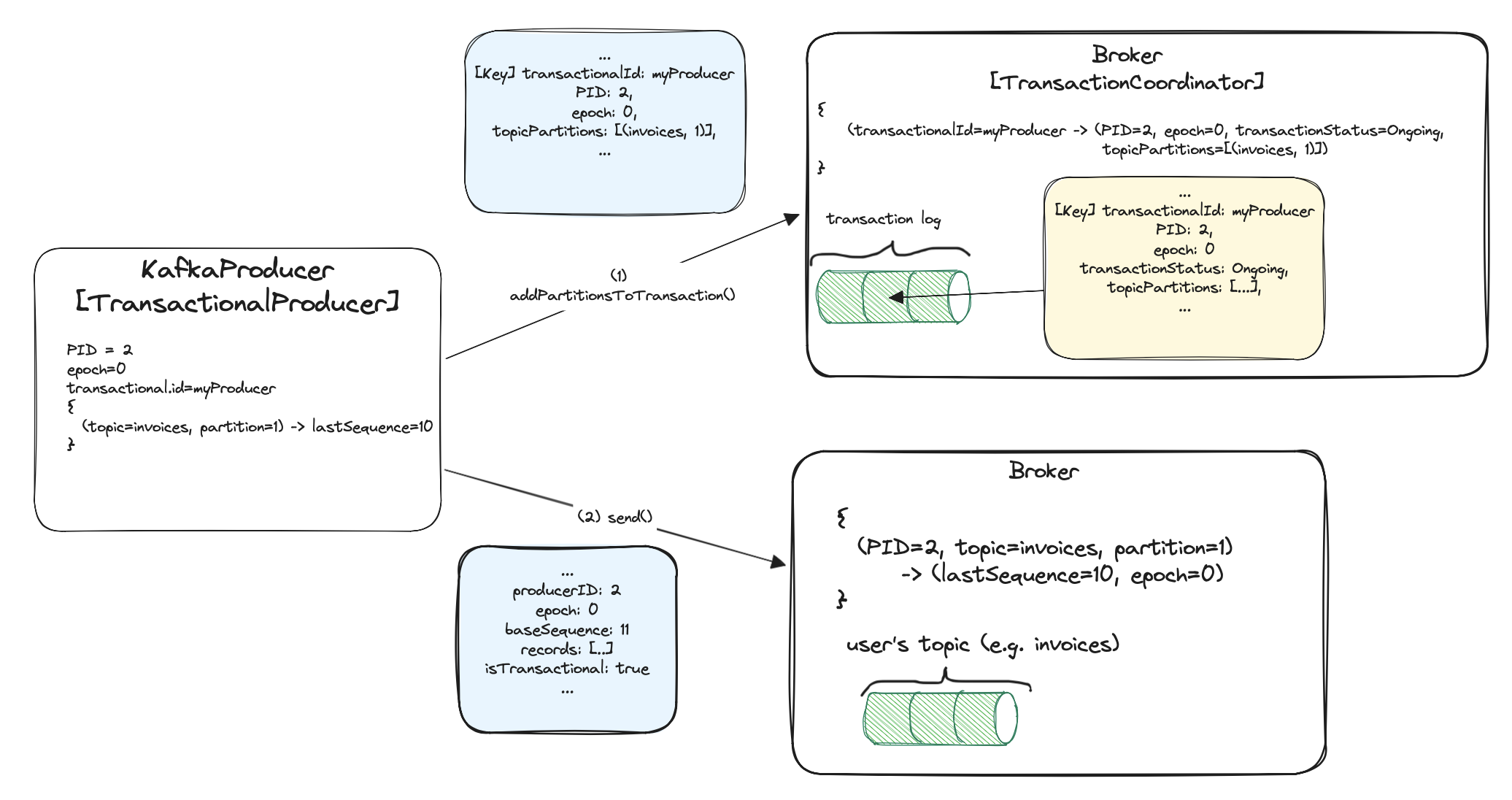
Before the transactional producer sends messages to the brokers, it has to record in the transaction coordinator,
to which topic partitions it’s sending messages. So it sends AddPartitionsToTxnRequest(1) to the coordinator. This information
is needed when committing/aborting a transaction. The AddPartitionsToTxnRequest is sent only once for each topic partition.
The coordinator will have to later know which brokers to inform about the transaction ending process.
The partitions are added to the coordinator’s in-memory map and also applied to the transaction log (and replicated).
The producer can now send messages to the brokers via ProduceRequest (2). The brokers reject duplicates because of PID included (idempotency).
They can also reject messages from zombie instances because of the presence of epoch. If the epoch is lower than expected,
the message is rejected. The brokers recognize if a message is transactional. It has isTransactional attribute set.
It will be important when returning the messages to the consumers with proper isolation levels. We’ll cover that later.
[INFO]
The actualProduceRequestis way more complex than in the picture. I’ve included only part of the request for one partition, which is important from the transactions’ standpoint.
Sending offsets to consumer coordinator
producer.sendOffsetsToTransaction(offsets, consumer.groupMetadata());
The offset committing in Kafka is a topic for a completely new blog post. I assume the reader knows the basics of consumer-groups and offset committing. If not, please read the following article.
We’ve consumed a message from the purchases topic and published invoice/shipment events to the target topics.
These are still invisible to the consumers with proper isolation level. Now we want to move forward on the purchases topic and commit consumed
offset. This fact has to be recorded in the transaction log and be the part of the transaction. Why? Once again, to get
atomicity and avoid duplicates. What if we consumed the purchase event, produced outgoing events to the target topics,
and before committing the offset for purchases the app crashed? After recovery, the app has to start consuming input topic at some point.
It is the last committed offset before the crash. But this one has already been consumed. Kafka solves that problem
by confining the offset commit as a part of the transaction: message consuming, producing, and offset committing happen together or
none of them.
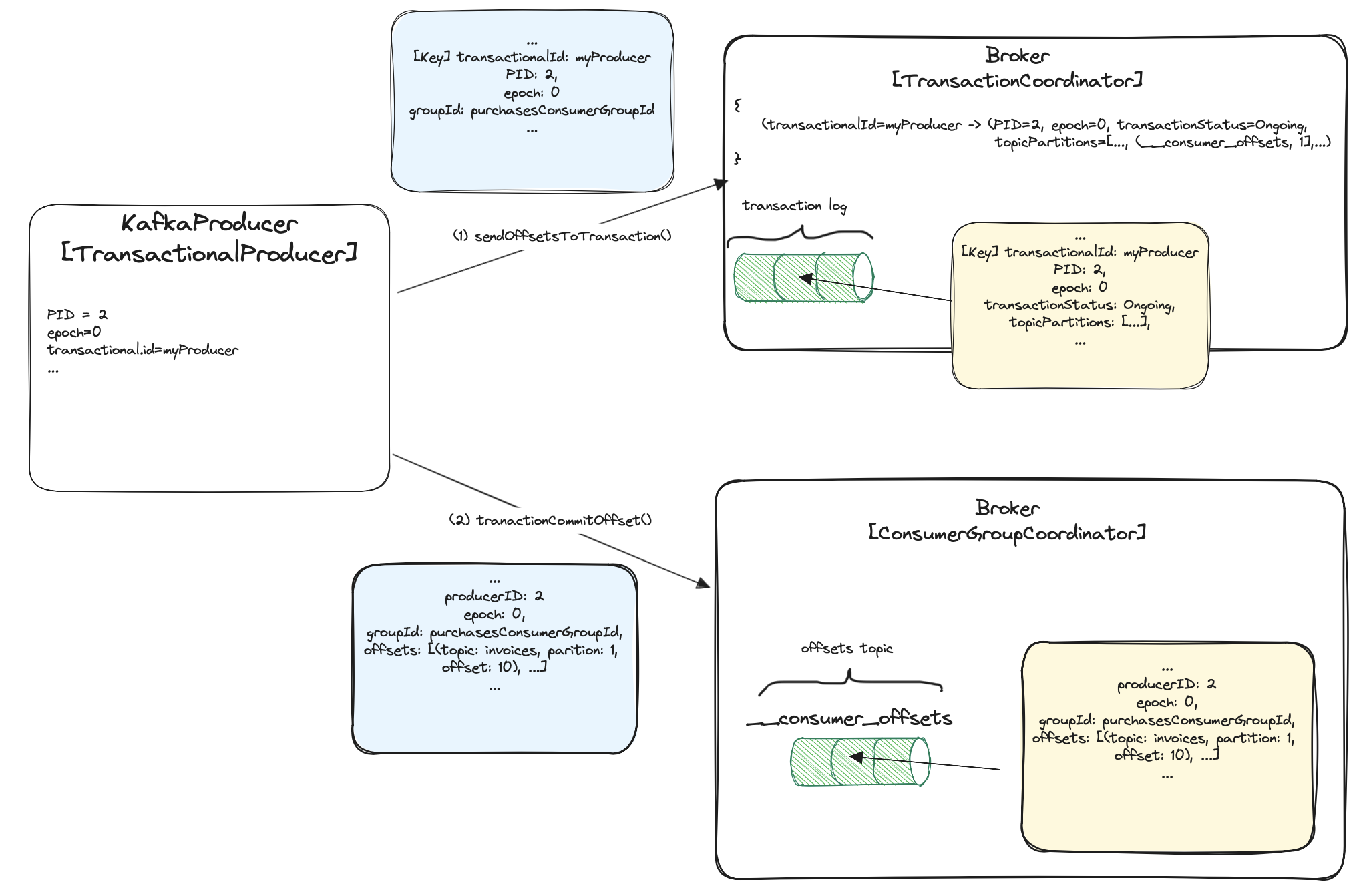
When adding offsets to a transaction, the producer sends AddOffsetsToTxnRequest (1) to the transaction coordinator.
It contains basic transactional fields which we’ve previously mentioned, and one additional field - consumer groupId.
Based on this, the transaction coordinator calculates __consumer_offsets topic partition for our consumer group
(the consumer group of the purchases topic consumer). You already know the algorithm. It is similar to one used in
finding a transactional coordinator.
var consumerOffsetsTopicPartitionId = hash(purchasesConsumerGroupId) % consumerOffetsTopicPartitionsCount;
As usual, it is added to the transaction coordinator state, and replicated via internal __transaction_state topic.
The calculated partitions will be then used when committing/aborting a transaction.
We notified the transactional coordinator about offsets, now it’s time to notify the consumer group coordinator.
Under the hoodKafkaProducer sends another TxnOffsetCommitRequest (2) to our consumer’s coordinator. How to find a consumer group
coordinator?
var consumerOffsetsTopicPartitionId = hash(purchasesConsumerGroupId) % consumerOffetsTopicPartitionsCount;
var coordinatorId = leaderOf(consumerOffsetsTopicPartitionId);
The request contains information about consumed topics partitions’ offsets. In our case, about consumed partitions of purchases topic.
The offset is appended to the __consumer_offsets topic, but it is not returned to the clients until the transaction commits.
Phew, a lot of work in a single function call. This is not the end. We still have a lot to cover.
Commit or abort
producer.commitTransaction(); // or we can call producer.abortTransaction() too
As in the databases world, a transaction can be committed or aborted. The commit materializes the transaction and consumers of the output topics can see its result. The abort makes all events in the transaction invisible. However, there is one requirement: you need to properly configure the consumer. Before that, let’s see what happens in the brokers.
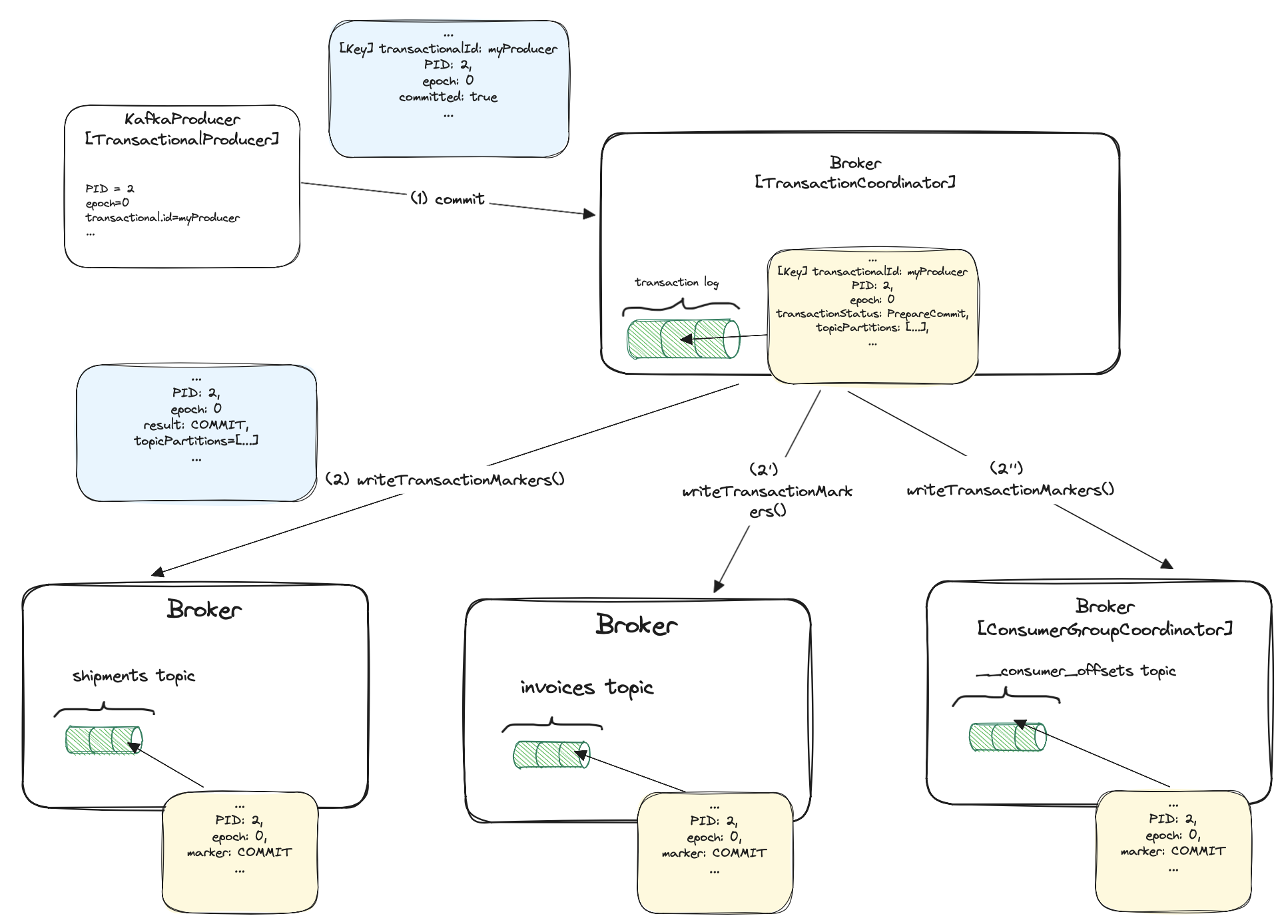
The producer sends EndTxnRequest (1) to the transaction coordinator. As usual, the request contains transactionalId,
PID, epoch, and a boolean committed indicating if to commit or abort. As usual, the request contains some other fields, I’ve just not included
them in the picture. The coordinator then starts a two-phase commit.
In the first phase, it updates its internal state and writes the PREPARE_COMMIT/PREPARE_ABORT
messages to the transaction log. Once the transaction state is fully replicated, the response is returned to the producer. At this point,
we can be sure the transaction is committed/aborted no matter what. If the coordinator crashes it can be replaced by a replica
having the full transaction log copy, which will end up the process.
The second phase is writing COMMIT/ABORT transaction markers to the leaders of topics partitions included in the transaction.
In our case, these are shipments, invoices and __consumer_offsets topics. The markers are appended via the
WriteTxnMarkerRequest (2, 2’, 2”). After that, the messages being part of the transaction can be finally returned to the consumers
with read_committed isolation level. For simple read_uncommitted consumers, the messages were returned earlier just after producing them to the brokers.
We’ll cover isolation levels later.
For the __consumer_offsets topic, the transaction coordinator has to write a marker to the consumer group coordinator
(consumer group of the consumer fetching from the input purchases topic).
The transaction coordinator has previously recorded the __consumer_offets partition (and commit offset) in the transaction log.
It now needs to find a leader for that partition - the consumer group coordinator. From this moment, depending on the marker type, the consumer group coordinator will
return proper offsets to its consumers. In case of the abort, it returns the input topic’s offsets before the transaction started.
In case of commit, it has to return offsets included in the transaction itself (offset after the position of the consumed event).
This way we don’t reprocess the same purchase event in case of a committed transaction.
The on-disk transactional messages
The on-disk transactional messages log (invoices topic):
root@kafka2:/tmp/kraft-combined-logs/invoices-0# /opt/kafka/bin/kafka-dump-log.sh --files 00000000000000000000.log
Dumping 00000000000000000000.log
Log starting offset: 0
...
baseOffset: 5 lastOffset: 5 count: 1 baseSequence: 0 lastSequence: 0 producerId: 2000 producerEpoch: 3 partitionLeaderEpoch: 0 isTransactional: true isControl: false deleteHorizonMs: OptionalLong.empty position: 558 CreateTime: 1709328801524 size: 134 magic: 2 compresscodec: none crc: 2337423005 isvalid: true
| offset: 5 CreateTime: 1709328801524 keySize: -1 valueSize: 64 sequence: 0 headerKeys: [] payload: {"userId":"u1","productId":"p1","quantity":2,"totalPrice":"20$"}
baseOffset: 6 lastOffset: 6 count: 1 baseSequence: -1 lastSequence: -1 producerId: 2000 producerEpoch: 3 partitionLeaderEpoch: 0 isTransactional: true isControl: true deleteHorizonMs: OptionalLong.empty position: 692 CreateTime: 1709328801679 size: 78 magic: 2 compresscodec: none crc: 2893569019 isvalid: true
| offset: 6 CreateTime: 1709328801679 keySize: 4 valueSize: 6 sequence: -1 headerKeys: [] endTxnMarker: COMMIT coordinatorEpoch: 0
The first one is a transactional invoice event, the second one is a COMMIT marker.
The on-disk transactional __consumer_offsets log:
root@kafka1:/tmp/kraft-combined-logs# /opt/kafka/bin/kafka-dump-log.sh --files __consumer_offsets-47/00000000000000000000.log --print-data-log
Dumping __consumer_offsets-47/00000000000000000000.log
Log starting offset: 0
...
baseOffset: 11 lastOffset: 11 count: 1 baseSequence: 0 lastSequence: 0 producerId: 2000 producerEpoch: 3 partitionLeaderEpoch: 0 isTransactional: true isControl: false deleteHorizonMs: OptionalLong.empty position: 2255 CreateTime: 1709328801657 size: 125 magic: 2 compresscodec: none crc: 914464467 isvalid: true
| offset: 11 CreateTime: 1709328801657 keySize: 33 valueSize: 24 sequence: 0 headerKeys: [] key: purchasesConsumerGroupId payload: �������y
baseOffset: 12 lastOffset: 12 count: 1 baseSequence: -1 lastSequence: -1 producerId: 2000 producerEpoch: 3 partitionLeaderEpoch: 0 isTransactional: true isControl: true deleteHorizonMs: OptionalLong.empty position: 2380 CreateTime: 1709328801679 size: 78 magic: 2 compresscodec: none crc: 2893569019 isvalid: true
| offset: 12 CreateTime: 1709328801679 keySize: 4 valueSize: 6 sequence: -1 headerKeys: [] endTxnMarker: COMMIT coordinatorEpoch: 0
The first one is an offset for consumer group fetching from source topic, the second one is a COMMIT marker.
Transactional consumer
We’ve already covered the producing side of the exactly once delivery. As mentioned before, the consumer has a role to play in the
process too. I’d like to clarify that below part of the post relates to the consumer consuming from the output transaction topics
(invoices and shipments). We can obviously consume from input topic in a transactional manner but let’s keep it simple to
comprehend now.
Transactional consumer usage
consumerProps.setProperty("group.id", "invoicesConsumerGroupId");
consumerProps.setProperty("isolation.level", "read_committed");
As usual, we have to provide a consumer group.id. The isolation level controls how to read messages written transitionally. From documentation:
If set to
read_committed, consumer.poll() will only return transactional messages which have been committed. If set toread_uncommitted, consumer.poll() will return all messages, even transactional messages which have been aborted.
The transaction markers are not
returned to the applications in either case.
The important thing is that even in read_committed mode there is no guarantee that a single consumer reads
all messages from a single transaction. It consumes transactional committed messages only from the assigned partitions. Transaction
can span multiple partitions from multiple topics. Part of them can be handled by different consumer instances from the
same consumer group (image below).
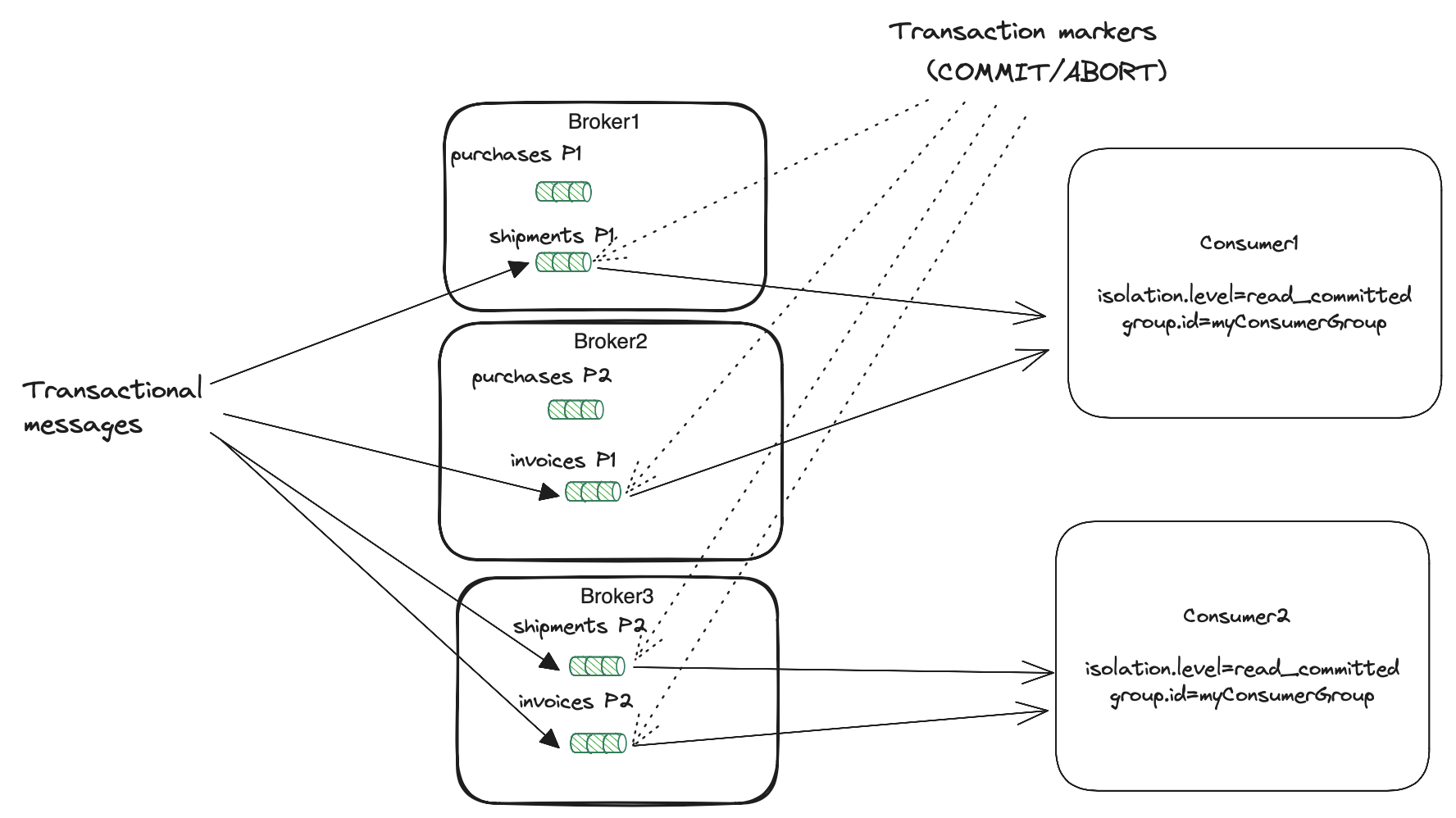
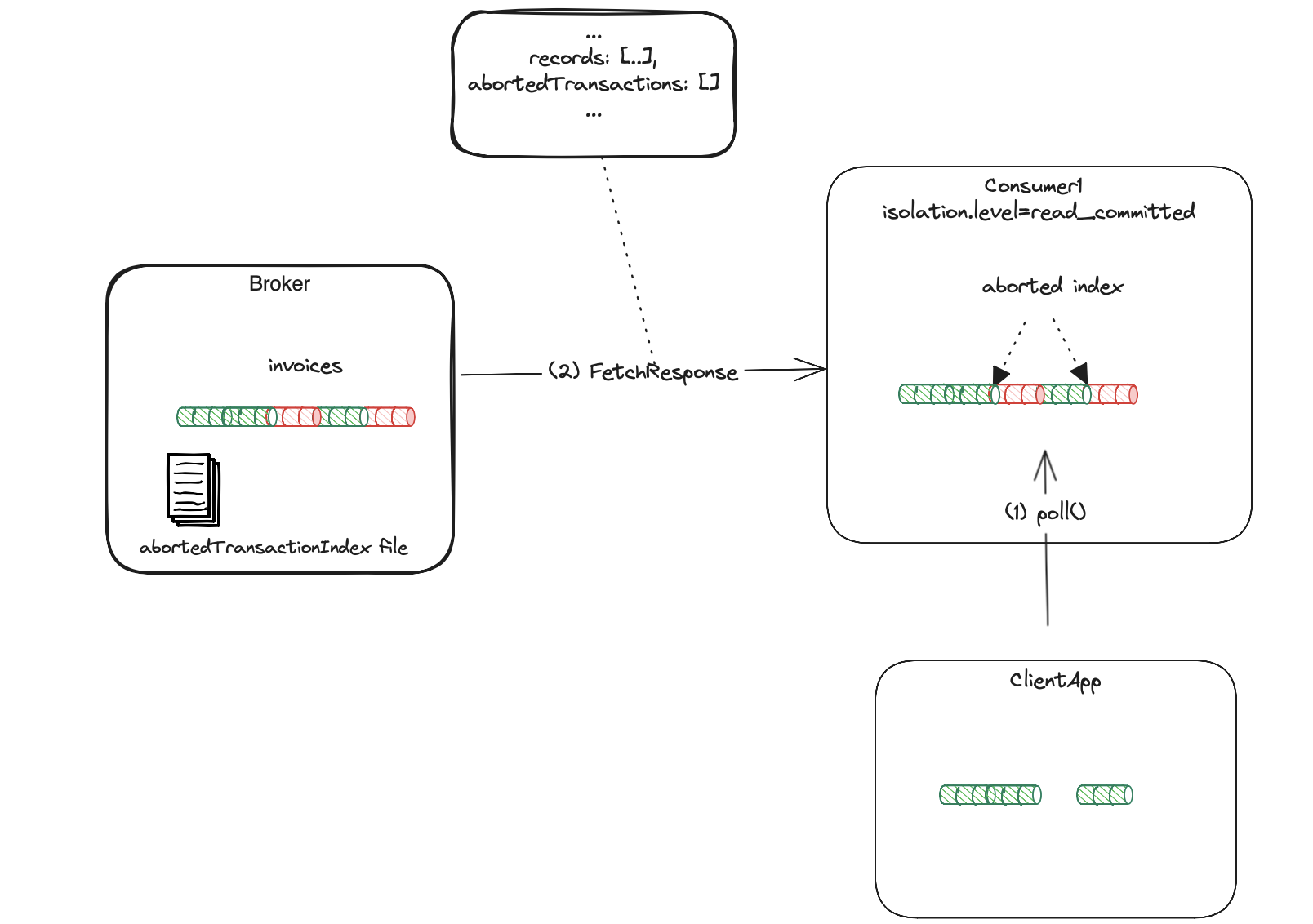
Broker’s LSO and aborted transaction index
The messages returned to the apps are always in their offset order. In a read_committed mode, the consumer has to know upfront which
messages are aborted, so they are not exposed to the clients. Take the following log as an example:
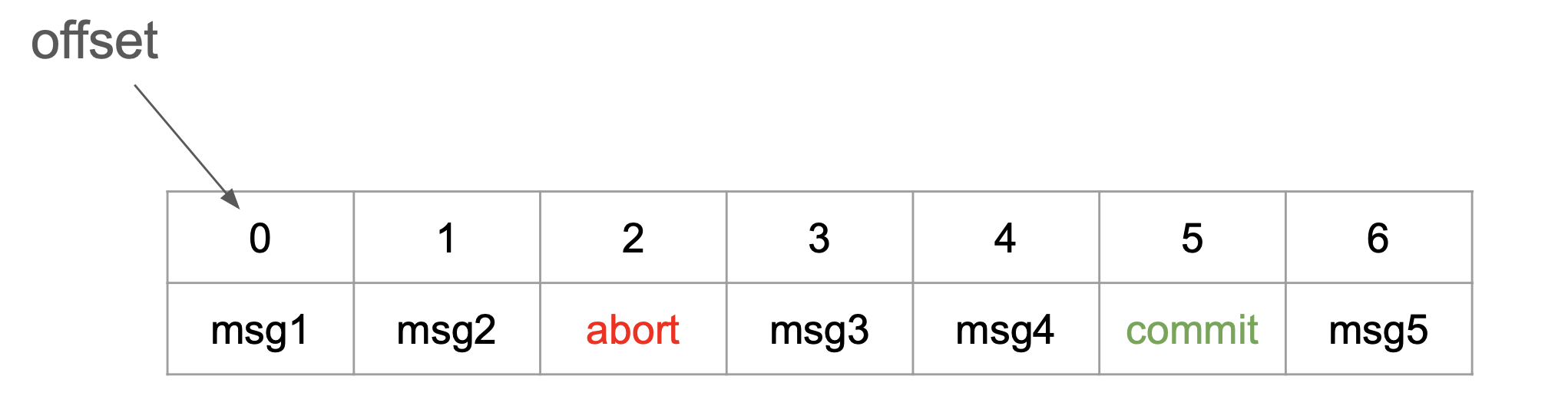
Let’s assume all messages in the log are transactional. While consuming messages in order, the consumer can’t return messages with offsets 0 and 1 to the client app.
In case of abort, it has to omit the offsets being part of the aborted transaction. In other words, the consumer needs some aborted messages filter.
This is the purpose of the aborted transaction index. Thanks to this structure, the consumers know where are the offsets of aborted messages,
so read_committed mode can filter them out. The index is built on the broker side and returned to the consumers in the FetchResponse
together with ordinary message data.
The on-disk index structure:
root@kafka2:/tmp/kraft-combined-logs/invoices-0# /opt/kafka/bin/kafka-dump-log.sh --files 00000000000000000000.txnindex
Dumping 00000000000000000000.txnindex
version: 0 producerId: 0 firstOffset: 0 lastOffset: 1 lastStableOffset: 2
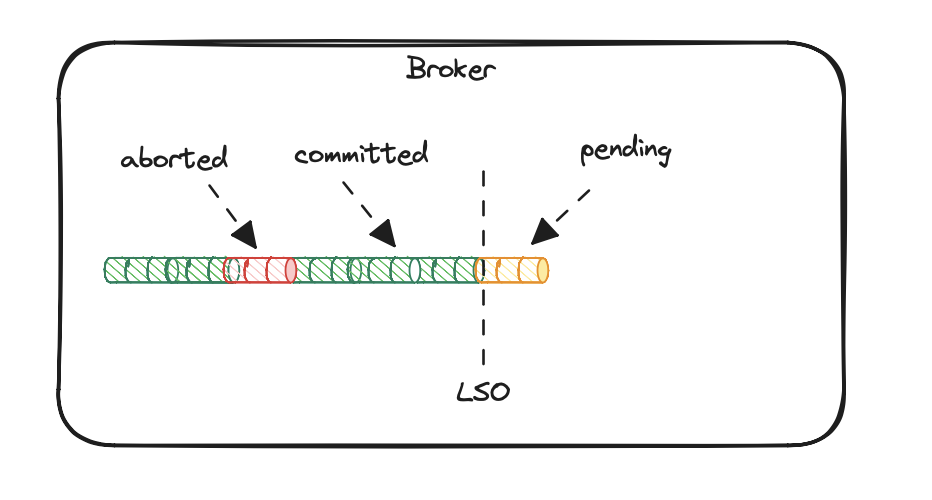
While returning messages to the read_committed consumer, the broker can return only resolved transactions. That means that any
pending transactions (without COMMIT/ABORT markers) will not be visible to the consumers until they end. To maintain such an invariant,
the broker keeps LSO (last stable offset) in its memory. It indicates the offset below which all transactions have resolved.
Without this, it would not be possible to build the transaction index, as pending transactions have no markers written yet.
Full transactional flow
Let’s put all steps in one picture.
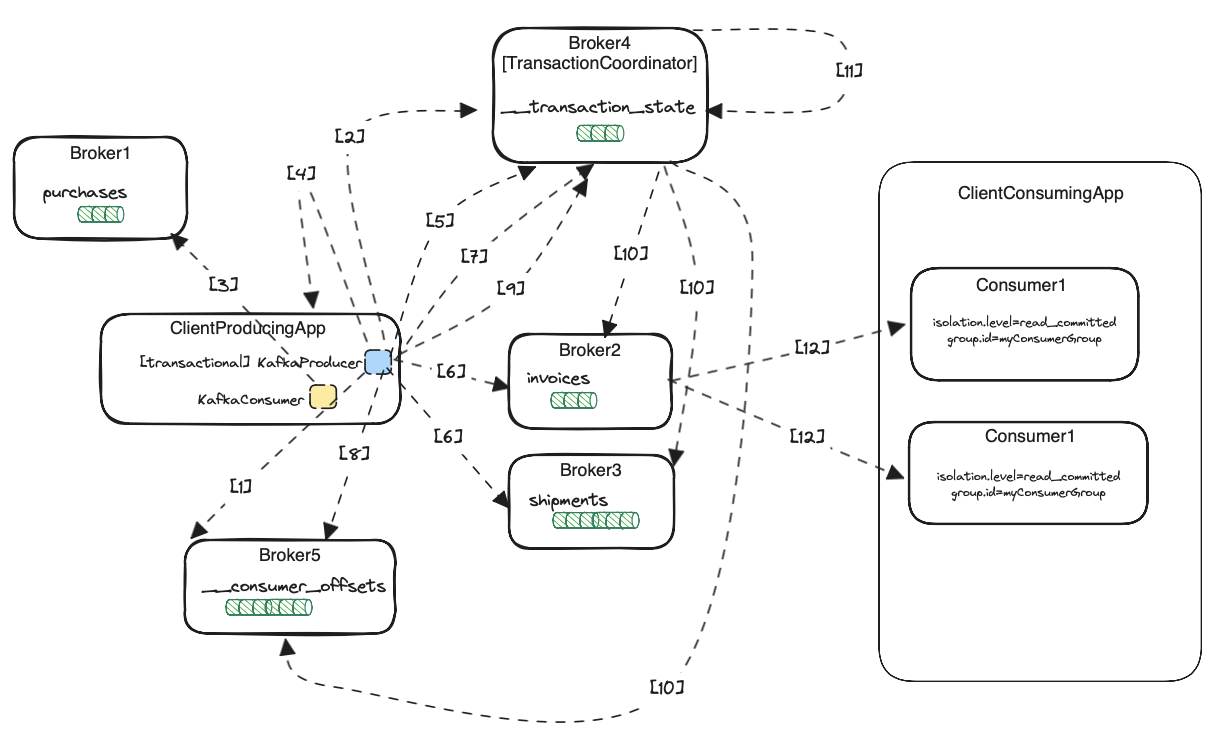
KafkaProducer.initTransactions()is called. The producer is part of theClientProducingAppapplication. TheFindCoordinatorRequest()is sent to any broker (Broker5 in the picture). The request containstransactionalIdused in calculating the transaction coordinator (Broker4).KafkaProduersendsInitPidRequestto the coordinator, in response it gets the producer idPIDwith some additional fields just like the producer epoch. This data is used both for idempotency and transactional API. It is then also stored in the brokers’ log.KafkaConsumer.poll()is called. The consumer is also part of the sameClientProducingAppapplication. The consumer uses thepurchasesConsumerGroupIdconsumer group. The app performs an atomic consume-transform-produce loop. It consumes events from thepurchasestopic and produces new events to theinvoicesandshipmentstopics as a single atomic unit. For the sake of better visibility, we have only one instance of the app. The app makes separate transaction for each record it gets from thepurchasestopic.KafkaProducer.beginTransaction()is called. No external requests, only internal producer state changes.KafkaProducer.send()method is called. Producer calculates target topic partition. It knows on which broker it is situated based on the internal metadata taken previously from the brokers. If it is the first message to this topic partition, the producer sendsAddPartitionsToTxnRequest()to the transaction coordinator. The coordinator updates its current transactions’ internal state, persists the information to the__transaction_statetopic, and waits for replication to follower replicas.- As part of the same
KafkaProducer.send()method from the previous point, the producer sends the messages (viaProduceRequest) to the leaders of calculated topic partitions. In our case, these are Broker2 forinvoicesand Broker3 forshipmentstopic. The messages are not sent immediately with asendcall because the producer is doing batching and sends them asynchronously. Nevertheless, they will be sent at some point. Besides the records itself, the request containsPID,epoch, and some other fields. It contains thetransactionalIdtoo, but only for authorization purposes. ThetransactionalIdis not persisted in the data topic (invoices/shipments) logs. KafkaProducer.sendOffsetsToTransaction()is called. The producer sendsAddOffsetsToTxnRequestto the transaction coordinator with a consumergroup.idas one of the fields. The coordinator calculates__consumers_offsettopic partition, records it to its internal state, and replicates the state via__transaction_statetopic to the followers.- As part of the same
KafkaProducer.sendOffsetsToTransaction()method from the previous point, the producer calculates the localKafkaConsumer’s consumer group coordinator. Producer then sends theTxnOffsetCommitRequestto the calculated coordinator. The request contains information about the consumer group offsets in thepurchasestopic’s partitions. The consumer group coordinator appends offsets to its internal__consumer_offsetstopic but does not return them to the consumer yet. It waits until the transaction is committed. KafkaProducer.commitTransaction()orKafkaProducer.abortTransaction()is called. The producer sendsEndTxtRequestto the transaction coordinator. The coordinator starts a two-phase commit. Firstly, it updates its internal transaction state toPREPARE_COMMIT/PREPARE_ABORT. It persists the state to the log and waits for replication to the followers.- In the second phase, the coordinator sends
WriteTxnMarkerRequest. It writes transactionCOMMIT/ABORTmarkers to the topic partitions included in transactions:invoices,shipments, and__consumer_offsets. In case of a coordinator crash, the information about transaction status is recorded in the__transaction_statelog. The new coordinator can start from the same point and continue ending the transaction process. For the__consumer_offsetstopic, the transaction coordinator takes the calculated (in point 7) topic partition, finds the consumer group coordinator, and sends an append marker request. - When the previous point succeeds the transaction coordinator updates its internal transaction state to
COMPLETE_COMMIT/COMPLETE_ABORTand the transaction is finished. - After successful transaction markers write, the brokers can now return new messages
to the consumers. The brokers move their LSOs (last stable offset) so they include the new messages.
The
ClientConsumingAppconsumes from target topics withread_committedmode. The call toKafkaConsumer.poll()sendsFetchRequest. The response contains new records together with an aborted transaction index. The consumer uses the index to filter out aborted transactions. In theread_uncommittedmode, the brokers return new messages immediately after append to the log in point 6.
Guarantees in failures scenarios
Finally, we know how everything works together. We can talk about Kafka exactly once delivery guarantees.
KafkaProducer.send()failure - this is the case when an error occurs during producing to target topics included in the transaction. The error can be a timeout or any other network problem. In this case, the producer will retry. Because transactions require idempotency, the retry is safe. If the broker has not yet received the message, it will accept a retried one. If it received the message, but the producer didn’t get the response, the producer retries using the previously sent sequence number. The broker rejects a message and returns aDUPLICATE_SEQUENCE_NUMBERerror response. This one however, can be ignored, and producing continues with the next message. No duplicates.KafkaProducerfailure - the producing application may fail or just can be restarted at any time. The newly created transactional producer invokesproducer.initTransactions()which sendsInitPidRequestwith the sametransactional.id. The transaction coordinator receiving this request aborts all ongoing transactions forPIDcurrently connected to the providedtransactionalId. In response, it returns the samePIDas for the old instance, but bumps the producer epoch. The aborted transactions from the old producer will never reach consumers with aread_committedisolation level. No duplicates.KafkaProducerhangs for a long time - the producing app can hang for any reason, e.g. long GC pause. In a distributed environment, an orchestration system like K8s can spawn a new instance when the first is not responding to the health check. What if after the second instance just started, the first ended the pause and continued producing? As in the previous case, the new instance initiates transactions withInitPidRequestsent to the coordinator. The coordinator bumps the producer epoch. The old producer is considered a zombie and will be fenced. Attempting to send a request to the coordinator with an old producer epoch, ends up withPRODUCER_FENCEDerror. Attempting to send a produce request with an old epoch to the broker results in anINVALID_PRODUCER_EPOCHerror. The brokers receiving messages know they need to bump producer epoch, because the transaction coordinator sent themABORTmarkers with increased epoch during new transaction initialization. No duplicates.KafkaConsumerfailure (the one consuming from the target topics) - let’s say that the application consuming from target transaction topics (invoices/shipments) sends requests to the external services. Usually, it gets a message from Kafka, sends requests, commits offsets, and the process repeats. What if the application crashed after sending requests, but before committing offsets? It will start processing transactional messages again, from the last committed offset, it will send duplicates. Transactions work only within Kafka topics. There is no protection from consuming committed transactions twice. Theread_committedisolation level only protects consuming aborted transactions. We would need external validation if specific messages were already processed by the external system. Duplicated processing may happen.- Transaction coordinator failure - the transaction coordinator replicates
__transaction_stateto follower replicas. In case of a crash, the new leader of this topic partition is elected. It becomes a new coordinator and continues handling transactions. There is no need to abort transactions started before the previous coordinator crash. The new one has been updating the in-memory state while replicating the log. TransactionalKafkaProducerlearns about the new leader by fetching metadata from other brokers. No duplicates. - Broker failure - the brokers receiving data
ProduceRequestmay fail too. A similar mechanism applies here as in the case of coordinator failure. The new data partition leader is elected. It previously replicated messages from the failed leader. It has been updating its in-memory state containingPIDtosequence_numbermapping.KafkaProduceridempotence enforcesack all. Data partition replicas have up-to-date sequence numbers. No duplicates. - Consumer group coordinator failure - consumer fetching from a source topic gets starting partition offsets form its
consumer group coordinator. The internal
__consumer_offsetstopic is replicated to the followers. If the current coordinator fails during the transaction, a new__consumer_offsetstopic partition leader is elected, and it becomes a new consumer group coordinator. The transaction will continue as normal. No duplicates.
Summary
Kafka transactions have introduced exactly once delivery guarantee. Quite a complex process hides
behind a few transactional producer calls. The guarantee works only inside Kafka itself. It is a foundation for Kafka Streams.
Nevertheless, it can be useful to build event-sourcing-like apps requiring atomicity of reading from input and producing to output topics.
For those who want to go deeper into the topic (non pun intended) read the original design doc.